Crawl là gì? 5 lỗi khiến Google không thể crawl data website đúng cách

Mục Lục
- I - Khái niệm Crawl
- II - Crawler ảnh hưởng đến SEO như thế nào?
- III - Trình thu thập thông tin (Crawler) hoạt động như thế nào?
- IV - Crawl data: Công cụ tìm kiếm có thể tìm thấy các trang của bạn không?
- V - Một số lỗi khiến Googlebot không thể Crawl trang web của bạn
- VI - Giúp công cụ tìm kiếm biết cách crawl trang web của bạn
- VII - Chặn Google crawl website
I - Khái niệm Crawl
1. Crawl là gì?
2. Crawler là gì? Ứng dụng của Web Crawler

3. Phân biệt Crawl và Scrap

II - Crawler ảnh hưởng đến SEO như thế nào?
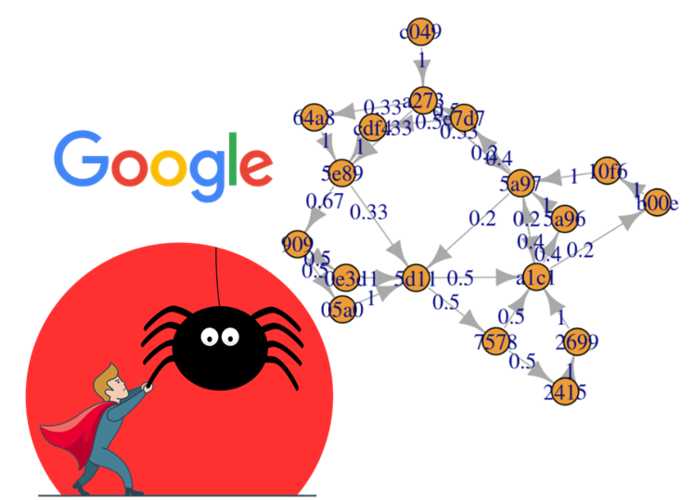
III - Trình thu thập thông tin (Crawler) hoạt động như thế nào?
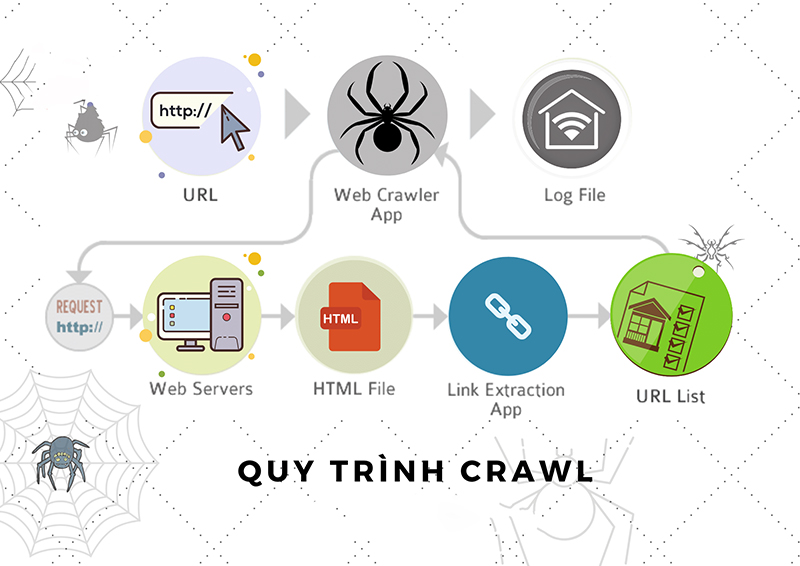
-
Thu thập thông tin: Tìm kiếm nội dung trên Internet, xem qua mã / nội dung cho từng URL mà bot tìm thấy
-
Lập chỉ mục: Lưu trữ và sắp xếp nội dung được tìm thấy trong quá trình thu thập thông tin. Khi một trang đã có trong chỉ mục, nó sẽ được hiển thị do kết quả của các truy vấn có liên quan
-
Xếp hạng: Cung cấp các phần nội dung sẽ trả lời tốt nhất cho truy vấn của người tìm kiếm, có nghĩa là các kết quả được sắp xếp theo thứ tự phù hợp nhất đến ít liên quan nhất
IV - Crawl data: Công cụ tìm kiếm có thể tìm thấy các trang của bạn không?
-
Trang web của bạn là thương hiệu mới và chưa được thu thập thông tin.
-
Trang web của bạn không được liên kết đến từ bất kỳ trang web bên ngoài nào.
-
Điều hướng trang web của bạn khiến rô bốt khó thu thập dữ liệu trang web một cách hiệu quả.
-
Trang web của bạn chứa một số mã cơ bản được gọi là chỉ thị trình thu thập thông tin đang chặn các công cụ tìm kiếm.
-
Trang web của bạn đã bị Google phạt vì các chiến thuật spam.
V - Một số lỗi khiến Googlebot không thể Crawl trang web của bạn
1. Nội dung ẩn sau các biểu mẫu đăng nhập
2. Sử dụng các biểu mẫu phương tiện không phải văn bản (hình ảnh, video, GIF, v.v.) để hiển thị văn bản mà bạn muốn được lập chỉ mục
3. Lỗi điều hướng trang web
-
Điều hướng trên thiết bị di động hiển thị kết quả khác với điều hướng trên máy tính để bàn.
-
Bất kỳ loại điều hướng nào mà các mục menu không có trong HTML, chẳng hạn như điều hướng hỗ trợ JavaScript. Google đã tiến bộ hơn nhiều trong việc thu thập thông tin và hiểu Javascript, nhưng nó vẫn chưa phải là một quá trình hoàn hảo. Cách chắc chắn hơn để đảm bảo thứ gì đó được Google tìm thấy, hiểu và lập chỉ mục là đưa nó vào HTML.
-
Cá nhân hóa hoặc hiển thị điều hướng duy nhất cho một loại khách truy cập cụ thể so với những người khác, dường như đang che giấu trình thu thập thông tin của công cụ tìm kiếm.
-
Quên liên kết đến một trang chính trên trang web thông qua điều hướng của bạn. Hãy nhớ rằng, liên kết là đường dẫn mà trình thu thập thông tin đi theo đến các trang mới.
4. Kiến trúc thông tin không rõ ràng
5. Thiếu sơ đồ trang web
VI - Giúp công cụ tìm kiếm biết cách crawl trang web của bạn

1. Chỉnh sửa hoặc tạo tệp robots.txt
-
Trên trang web của bạn: https://example.com/robots.txt
-
Trên máy chủ của bạn: /home/userna5/public_html/robots.txt
2. Cách Googlebot xử lý tệp robots.txt
-
Nếu Googlebot không thể tìm thấy tệp robots.txt cho một trang web, nó sẽ tiến hành thu thập dữ liệu trang web.
-
Nếu Googlebot tìm thấy tệp robots.txt cho một trang web, nó thường sẽ tuân theo các đề xuất và tiến hành thu thập dữ liệu trang web.
-
Nếu Googlebot gặp lỗi khi cố gắng truy cập vào tệp robots.txt của trang web và không thể xác định xem tệp đó có tồn tại hay không, nó sẽ không thu thập dữ liệu trang web.
VII - Chặn Google crawl website

Việc crawl website giúp cho Google hiểu rõ hơn về cấu trúc website giúp chiến dịch SEO Onpage được triển khai tối ưu và thuận lợi hơn. Ngoài ra các SEOer có thể áp dụng chiến lược SEO Onpage mà Ori đưa ra nhằm tối ưu hiệu quả nhất.
- Tags
Tác giả

Vũ Việt Hoàng



